FDIS: Functional Dependency Information System
 FDIS Benutzeroberfläche - Normalisierung und Visualisierung
FDIS Benutzeroberfläche - Normalisierung und VisualisierungProjektübersicht
FDIS (Functional Dependency Information System) ist ein Informationssystem für funktionale Abhängigkeiten in PostgreSQL-Datenbanken. Es ermöglicht:
✓ Visualisierung funktionaler Abhängigkeiten (FDs)
✓ Manipulation von FDs durch grafische Benutzeroberfläche
✓ Automatische Normalisierung relationaler Datenbankschemata
✓ Direkte Implementierung der Normalisierung in der bestehenden Datenbank
Kernfunktionalität
Automatische Normalisierung
Anders als reine Lehrsysteme, die nur theoretische Normalisierungen durchführen, implementiert FDIS die Zerlegung direkt in der Datenbank:
- Funktionale Abhängigkeiten erfassen – Tabellarische oder grafische Eingabe von FDs
- Schlüsselkandidaten berechnen – Automatische Bestimmung aller möglichen Kandidatenschlüssel
- Normalform analysieren – Prüfung des aktuellen Normalisierungsgrades (3NF, BCNF)
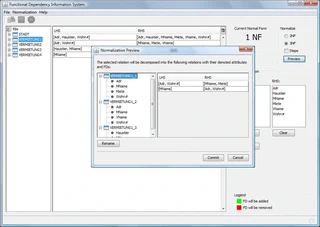
- Schema zerlegen – Algorithmische Zerlegung auf gewünschte Normalform
- In Datenbank implementieren – Automatische Erstellung neuer Relationen, Umverteilung der Daten
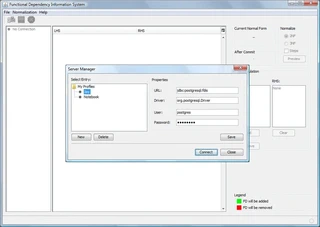
Benutzeroberfläche
Die GUI wurde mit besonderem Fokus auf Benutzerfreundlichkeit und Robustheit entwickelt:
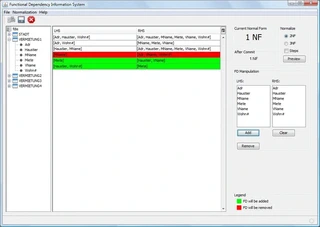
- Tabellarische Darstellung funktionaler Abhängigkeiten (skaliert besser als graphische Formen bei vielen FDs)
- Interaktive Manipulation – Hinzufügen, Ändern, Löschen von FDs
- Echtzeit-Validierung – Sofortige Rückmeldung über Datenbankstatus
- Visualisierung der Zerlegung – Verständliche Darstellung der Normalisierungsschritte
- One-Click-Normalisierung – Automatische Umsetzung mit Bestätigungsdialog
Anwendungsgebiete
1. Lehre und Ausbildung
Optimale Lernwerkzeuge für Studenten:
- Interaktives Verständnis von Normalisierungskonzepten
- Hands-on-Erfahrung mit echten Datenbanken (nicht nur Theorie)
- Direkte Konsequenzen der Normalisierungsentscheidungen sichtbar machen
Werkzeug für Lehrende:
- Einfache Erstellung von Übungsaufgaben
- Automatische Überprüfung von Studentenlösungen
- Klare visuelle Rückmeldung über Korrektheit
2. Praktische Datenbankverbesserung
Bewertung und Optimierung bestehender Schemata:
- Analyse schlecht normalisierter Legacy-Datenbanken
- Identifikation funktionaler Abhängigkeiten in produktiven Systemen
- Gezielte Verbesserung von Datenbankdesigns
- Automatische, sichere Implementierung von Verbesserungen
Technische Eigenschaften
Architektur
| Komponente | Details |
|---|---|
| Datenbank | PostgreSQL (relationales DBMS) |
| Algorithmen | Zerlegung nach 3NF-Norm |
| Komplexität | NP-vollständig (Bestimmung von Kandidatenschlüsseln) |
| Skalierung | Stabil auch bei größeren Datenbanken |
Performance
Ergebnisse der Performanceanalyse (Kapitel 7.1):
✓ Schnelle Ausführung – Auch bei relativ großen Datenbanken und Relationen
✓ Stabile Laufzeit – Keine kritischen Bottlenecks im normalen Betrieb
⚠️ Speicherverbrauch – Bei Relationen mit vielen Attributen (>~20) können Speicheranforderungen steigen (unvermeidlich wegen NP-Vollständigkeit)
→ Fazit: Für typische Anwendungsszenarien (Lehre, mittlere Datenbanken) vollkommen ausreichend
Design-Entscheidungen
Tabellarische statt grafische Darstellung
Bewusste Designentscheidung:
- ❌ Graphische Formen: Werden bei vielen FDs schnell unübersichtlich
- ✅ Tabellen: Skalieren gut für beliebig große FD-Mengen
- Resultat: Klare, wartbare Darstellung auch in komplexen Fällen
Auf 3NF fokussieren
Normalformen-Strategie:
- 3NF: Praktisch relevant, Standard in industriellen Systemen, ausgeglichener Kompromiss
- BCNF: Theoretisch interessant, aber praktisch weniger wichtig
- 4NF/5NF: Eher akademisch, erfordern MVDs (Multi-Valued Dependencies)
- Resultat: Fokus auf praktikabler, häufig benötigter Normalform
Potenzielle Weiterentwicklungen
Kurzfristig (geringer Aufwand)
- BCNF-Normalisierung: Modularer Aufbau ermöglicht einfach neuen Zerlegungsalgorithmus
Langfristig (höherer Aufwand)
- 4NF/5NF Support: Neue Datenstrukturen und Algorithmen für MVDs nötig
- Graphische FD-Diagramme: Ergänzende Visualisierung (neben Tabellen)
- Weitere Datenbanksysteme: MySQL, Oracle, SQL Server Support
Nicht geplant
- Höhere Normalformen (4NF+) – Geringe praktische Relevanz für Lehrzwecke
- Reine grafische Darstellung – Skalierungsprobleme, Tabellen ausreichend
Wissenschaftlicher Hintergrund
Entwickelt im Rahmen einer Bachelor-Arbeit mit Fokus auf:
- Relationale Entwurfstheorie – Grundkonzepte
- Algorithmische Lösungen – Für funktionale Abhängigkeiten und Normalisierung
- Softwarearchitektur – Modulares, wartbares Design
- Benutzerinterface – Praktische Anwendbarkeit im Echtbetrieb
Lizenz & Code
Der komplette Source Code ist auf GitHub verfügbar: → timpner/fdis
Hinweis: Projektdokumentation primär in Deutsch verfügbar. Für Fragen in Englisch bitte Issues auf GitHub erstellen oder direkt kontaktieren.
Zielgruppe
- 👨🎓 Informatik-Studenten – Lernen von Datenbanktheorie
- 👨🏫 Dozenten – Unterrichtsunterstützung und Aufgabenerstellung
- 🏢 Datenbankadministratoren – Schema-Optimierung und Normalisierung
- 🔬 Forscher – Basis für weitere DB-Design-Tools